Overview¶
The Design Studio is used to chain together multiple models, along with data translation tools, filters and output adapters, into a full end-to-end solution which can then be deployed into any runtime environment.
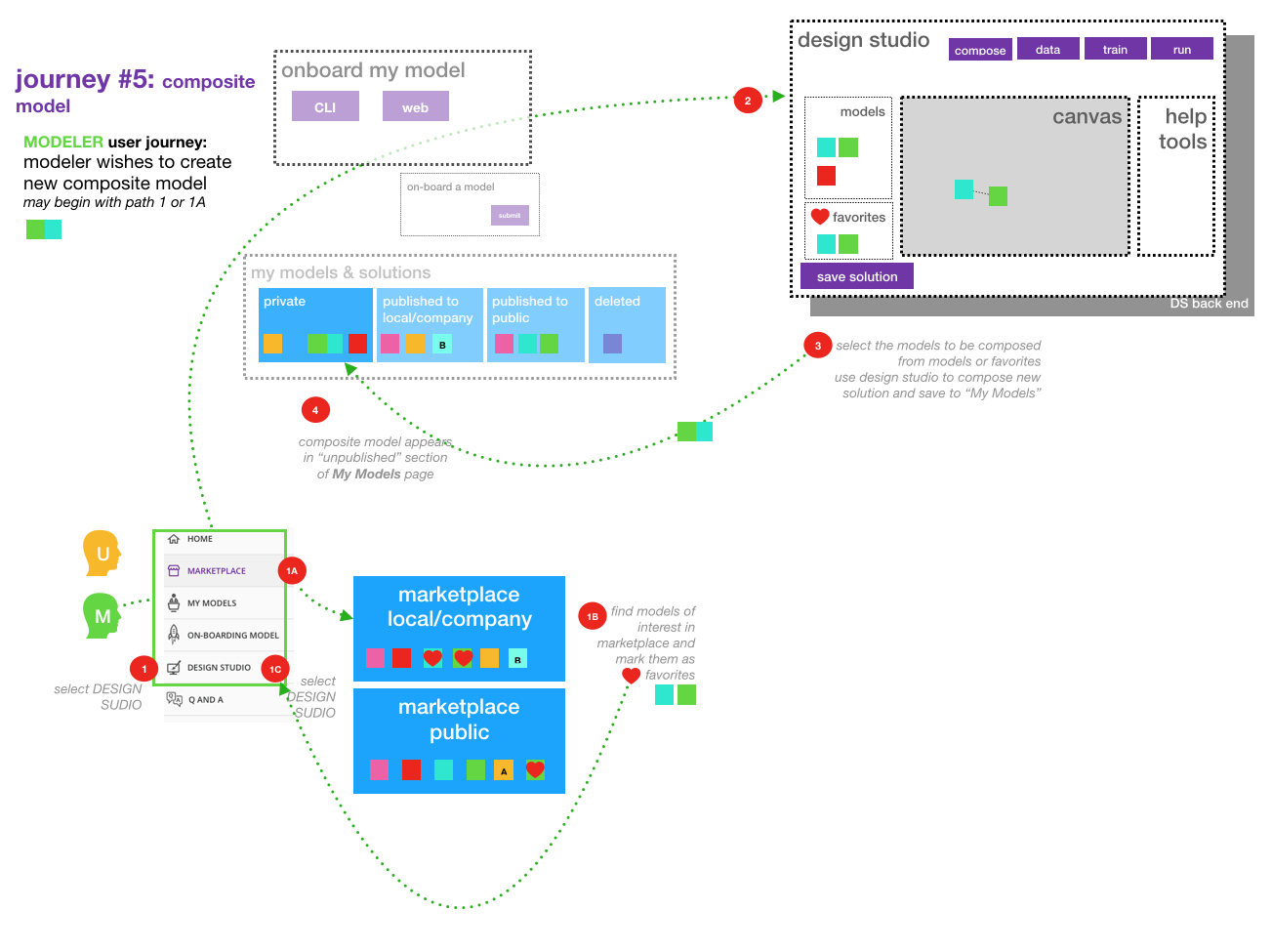
An overview of the user journey for the Design Studio is shown below.
Architecture¶
ML Models are the basic building blocks in the Design Studio. It is these models that are combined together by the designer to create complex ML application – aka composite solutions.
ML Models – Isolated and Standalone¶
ML Models are developed and contributed by ML subject matter experts. They may be written in any programming language and may have been developed in any toolkit – Scikit, Tensor Flow, R, H2O, etc.
The model developer may not necessarily be aware of the existence of other models. The models are usually standalone entities. They offer a standard contract – an interface definition to the external world. This contract specifies the details of the operation performed by the model, the input request (message) consumed by the model and the output response (message) produced by the model. In Acumos, this contract is specified in the Protobuf file.
ML Models – Ports, Requirements and Capabilities¶
Each ML Model may support one or more operations – corresponding to the functions, such as “prediction,” “classification,” etc., performed by the model. Each operation consumes an input message and produces an output message. The message signatures are specified in the Protobuf file.
Each operation is represented by two ports – an input port and an output port. An ML model may have more than two ports, if it provides (exposes) multiple operations (aka services).
- Input Port - consumes the input message and provides the service, such as prediction or classification or regression to the caller/client. The input port represents the capability of the model. The client that need a service to be performed need to send a request to input or the capability port of the model.
- Output Port – produces the output (response) message. Note that the output produced by an operation (say the Prediction message) need not necessarily be consumed by the caller/client, but in fact needs to be fed to another ML Model which provides another service, such as classification (of the Prediction message). So from a composition perspective, the output port represents a requirement that is satisfied by classification service.